Evoluzione dei modelli di linguaggio GPT
L'evoluzione dagli RNN ai Transformer ha rivoluzionato l'elaborazione del linguaggio naturale, rendendo i modelli più scalabili, efficienti e potenti.
Indice
Introduzione
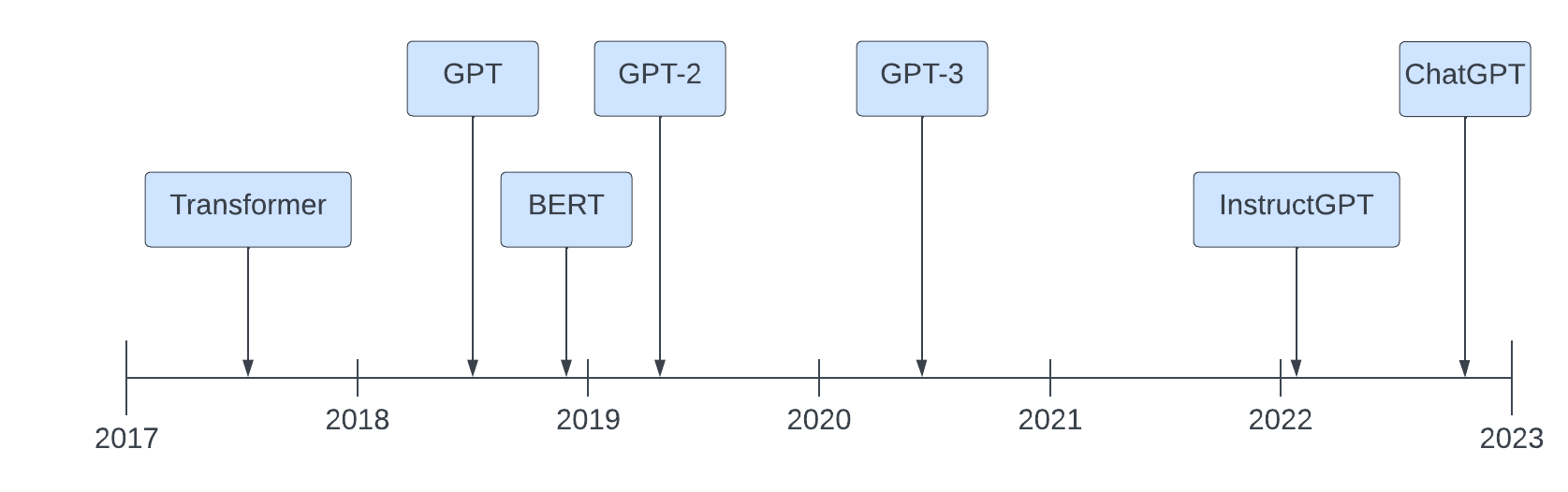
Come siamo arrivati ai Large Language Models (LLM) moderni? Il percorso che ha portato alla creazione di modelli come GPT-4 è iniziato con la scoperta dell'architettura Transformer da parte di Google nel 2017, seguita dagli studi di OpenAI sui Scaling Laws e la continua evoluzione della capacità computazionale e dei dataset. In questo articolo esploreremo la storia di questa rivoluzione tecnologica.
Transformer
Nel 2017, Google ha introdotto il concetto di Transformer, un'architettura di rete neurale che ha rivoluzionato il modo in cui i modelli elaborano il linguaggio naturale. Questo sistema si basa su una struttura in grado di elaborare intere sequenze di testo in parallelo, a differenza delle reti neurali ricorrenti (RNN) che elaboravano parola per parola, risultando più lente e meno efficienti.
Uno degli elementi chiave dei Transformer è il meccanismo di self-attention, che permette al modello di dare più importanza a determinate parole in un contesto, indipendentemente dalla loro posizione nella frase. Questo ha consentito un salto di qualità nella comprensione e generazione del linguaggio naturale, migliorando traduzioni, riepiloghi e risposte automatiche.
Grazie a questa innovazione, il Transformer ha rapidamente sostituito le precedenti architetture basate su LSTM e RNN, diventando il punto di riferimento per lo sviluppo di modelli di linguaggio di grandi dimensioni. Le RNN elaboravano il linguaggio in modo sequenziale, tenendo conto solo del contesto immediato, mentre le LSTM miglioravano questa tecnica introducendo una memoria a lungo termine che consentiva di gestire dipendenze più lontane nel testo. Tuttavia, entrambe queste architetture soffrivano di problemi di scalabilità e difficoltà nel catturare relazioni complesse tra le parole a grandi distanze.
Il Transformer ha segnato un salto evolutivo grazie al meccanismo di self-attention, che consente al modello di valutare contemporaneamente l'intera sequenza di testo, identificando connessioni tra parole distanti e migliorando notevolmente la comprensione contestuale. Questo ha permesso di eliminare le limitazioni delle reti sequenziali, rendendo il processo di addestramento più efficiente e migliorando la qualità delle generazioni testuali.
Questa tecnologia ha gettato le basi per la nascita di sistemi sempre più avanzati, come la serie GPT di OpenAI, che ha dimostrato come aumentando la scala dei modelli e dei dataset sia possibile ottenere una comprensione del linguaggio simile a quella umana, aprendo nuovi orizzonti per l'intelligenza artificiale generativa.
Scaling
Nel 2018, OpenAI ha scoperto le Scaling Laws, ovvero le leggi di scalabilità che regolano la crescita delle prestazioni dei modelli in relazione alla loro dimensione, alla quantità di dati di addestramento e alla potenza computazionale. Queste leggi hanno rivelato che il miglioramento dei modelli non è lineare, ma segue un comportamento prevedibile basato su tre variabili fondamentali: il numero di parametri, la disponibilità di dati e la potenza di calcolo.
L'osservazione chiave è stata che aumentando in modo proporzionale queste tre componenti, le capacità dei modelli migliorano in maniera significativa. Questo ha portato OpenAI e altre aziende a investire massicciamente nell'espansione delle risorse computazionali e nella raccolta di dataset sempre più ampi e variegati per ottimizzare la qualità dell'apprendimento automatico.
Di conseguenza, le Scaling Laws hanno rappresentato un punto di svolta nello sviluppo degli LLM, permettendo la creazione di modelli come GPT-3 e GPT-4, che hanno ridefinito il concetto di intelligenza artificiale generativa, rendendola sempre più accessibile ed efficace nel comprendere e generare linguaggio naturale.
GPT-1
Nel 2019, OpenAI ha introdotto GPT-1, il primo modello basato su Transformer, con 150 milioni di parametri. Pur essendo un primo esperimento, ha dimostrato la validità dell'approccio e ha gettato le basi per i futuri sviluppi.
GPT-2
Sempre nel 2019, OpenAI ha rilasciato GPT-2, un modello significativamente più grande con 1,5 miliardi di parametri. Questo modello ha mostrato notevoli miglioramenti nella generazione di testo, al punto che inizialmente OpenAI ha esitato a rilasciare il modello completo per timore di un uso improprio.
GPT-3
Nel 2020, OpenAI ha presentato GPT-3, un gigantesco passo avanti con 175 miliardi di parametri. Questo modello ha dimostrato una straordinaria capacità di comprendere e generare linguaggio naturale in maniera più fluida e contestuale, diventando una pietra miliare nel campo dell'IA generativa.
GPT-4
Nel 2022, OpenAI ha introdotto GPT-4, un modello ancora più avanzato, con un numero di parametri stimato nell'ordine dei trilioni. Questa versione ha migliorato la comprensione contestuale, la generazione di testo più coerente e la capacità multimodale, ossia la possibilità di elaborare sia testo che immagini.