La Distillazione nell’IA spiegata in modo semplice
DeepSeek ha utilizzato GPT-4 come teacher per distillare un modello più leggero, sfruttando tecniche di black-box querying per replicarne il comportamento senza accesso diretto al sistema proprietario.
- Introduzione
- Un’Analogia per Comprendere la Distillazione
- Come Funziona la Distillazione
- Come DeepSeek ha Utilizzato la Distillazione
- Vantaggi e Applicazioni della Distillazione
Introduzione
Nel mondo dell’intelligenza artificiale, la distillazione è una tecnica che permette di creare modelli più leggeri e veloci senza sacrificare troppo le loro prestazioni. Ma cosa significa in termini semplici? Immagina di prendere le conoscenze di un esperto in un campo complesso e trasferirle in modo efficace a un apprendista, rendendolo capace di svolgere gran parte delle attività del maestro. Questo è, in sostanza, ciò che fa la distillazione nell’AI.
Un’Analogia per Comprendere la Distillazione
Immagina una grande enciclopedia piena di informazioni su ogni argomento. Ora, pensa a un compendio più piccolo che riassume i punti chiave dell’enciclopedia, rendendoli più facili da consultare e più veloci da leggere. La distillazione nell’AI funziona in modo simile:
- L’enciclopedia rappresenta un modello grande e complesso (chiamato teacher model), capace di gestire informazioni dettagliate e complesse.
- Il compendio è un modello più piccolo (student model), che apprende i punti fondamentali dall’enciclopedia per svolgere il suo lavoro in modo più snello.
- Il processo di sintesi rappresenta la distillazione, dove il compendio viene creato sintetizzando le informazioni più importanti dell’enciclopedia.
Questa tecnica permette di creare modelli AI che consumano meno risorse, ma che sono ancora capaci di svolgere compiti complessi con un alto livello di precisione.
Come Funziona la Distillazione
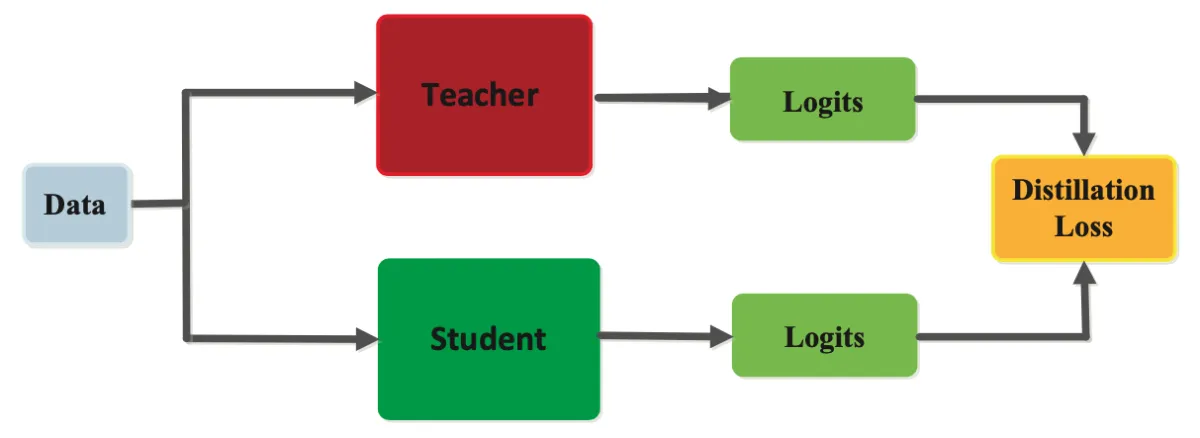
La distillazione si basa su un processo strutturato che trasferisce le conoscenze da un modello grande (teacher) a uno più piccolo (student). Ecco i passaggi fondamentali:
Il Modello Teacher
Il teacher model è un sistema complesso e potente, addestrato su grandi quantità di dati. Questo modello è capace di fare previsioni precise e comprende dettagli sottili grazie alla sua struttura avanzata. Per esempio, un modello teacher potrebbe distinguere non solo tra cani e gatti, ma anche tra diverse razze con un alto grado di accuratezza.
Le Soft Labels
Il modello teacher non insegna semplicemente risposte giuste o sbagliate. Genera invece soft labels, che rappresentano probabilità complesse per ogni possibile risposta. Ad esempio, se il teacher analizza un’immagine di un gatto, potrebbe dire:
- 90% gatto
- 7% volpe
- 3% cane
Queste soft labels danno al modello student informazioni più ricche rispetto a una risposta binaria ("è un gatto" o "non è un gatto"). Questo è cruciale per trasferire conoscenze approfondite.
Il Modello Student
Il student model è progettato per essere più piccolo e leggero. Viene addestrato utilizzando le soft labels del teacher model, apprendendo così i dettagli più importanti senza dover elaborare l’intero set di dati originale. Questo gli consente di raggiungere prestazioni elevate pur essendo meno esigente in termini di risorse.
Come DeepSeek ha Utilizzato la Distillazione
DeepSeek, un’azienda cinese emergente nel settore dell’intelligenza artificiale, ha sfruttato la distillazione per superare limitazioni tecnologiche e creare modelli altamente competitivi. Il modello teacher scelto da DeepSeek è stato basato su GPT-4, un sistema robusto sviluppato da OpenAI. Tuttavia, sorge una domanda interessante: come è stato possibile utilizzare GPT-4, essendo questo un sistema proprietario?
Accesso Indiretto al Modello Teacher
DeepSeek non ha avuto accesso diretto al codice sorgente o ai parametri di GPT-4, ma ha utilizzato una tecnica chiamata black-box querying. Questo approccio consiste nel sottoporre un modello AI, come GPT-4, a una serie di domande specifiche, raccogliendo le risposte generate. In questo modo, DeepSeek ha potuto osservare il comportamento del modello e replicarlo:
- Creazione di Dataset Mirati: DeepSeek ha formulato milioni di domande al modello GPT-4, coprendo una vasta gamma di scenari e raccogliendo le risposte dettagliate. Questi dati sono stati utilizzati per generare soft labels di alta qualità.
- Addestramento del Modello Student: Con le soft labels ottenute, DeepSeek ha addestrato un modello student in grado di emulare le prestazioni di GPT-4 su compiti specifici, senza necessità di accedere direttamente al modello originale.
- Ottimizzazione per Risorse Limitate: Il modello student è stato ulteriormente ottimizzato per funzionare in contesti con risorse computazionali ridotte, mantenendo alti standard di precisione.
Questa strategia innovativa dimostra come sia possibile aggirare le restrizioni legate all’accesso a sistemi proprietari, utilizzando un approccio indiretto per ottenere risultati comparabili.
Vantaggi e Applicazioni della Distillazione
La distillazione offre numerosi vantaggi, rendendola una tecnica essenziale nell’AI moderna:
- Efficienza Computazionale: I modelli student sono più veloci e richiedono meno potenza di calcolo, rendendoli ideali per dispositivi mobili o sistemi con risorse limitate.
- Riduzione dei Costi: Con modelli più leggeri, le aziende possono ridurre i costi legati all’elaborazione e all’archiviazione dei dati.
- Flessibilità: I modelli distillati possono essere facilmente adattati a diversi scenari, come applicazioni in tempo reale o ambienti con connessioni limitate.
- Accesso Democratizzato all’AI: La distillazione consente anche a chi non ha accesso a hardware avanzato di utilizzare modelli AI avanzati.
Le applicazioni sono molteplici, dalle app di traduzione in tempo reale ai sistemi di riconoscimento vocale, fino ai software di analisi delle immagini.